What’s the probability of two people sharing the same last 4 digits of a telephone number in a waiting room?
Probability
Python
Author
Hector
Published
Wednesday, November 1, 2023
Some medical waiting rooms use the last 4 digits of a phone number (in America at least) as a unique and private identifier for patients. When checking in, the patients provide their phone number and then they can check wait times on a screen that displays a list of the last 4 digits of phone numbers. In addition to quasi-anonymity, I think this system also has the benefit of allowing an automated audio system to call a person by their number, rather than mangle a last name. But I recently began to wonder how frequently there might be a collision, where two people in the waiting room share the same last 4 digits of their phone numbers. I couldn’t stop thinking about it, so I decided to find out.
North American Telephone System
In America, we have a 10-digit telephone system with three sections:
Figure 1: Schematic of North American telephone number
area code: unique code assigned to a geographic (mostly) region
telephone prefix: unique code assigned to smaller regions within an area code
line number: 4-digit code unique within area code+telephone prefix
In theory, if all phone numbers were available and valid (they’re not), there could be at most 1010 (10,000,000,000) telephone numbers in North America.
Considering the 4-digit line number, there would be 104 (10,000) unique numbers. Out of 10,000 possible line numbers, what are the chances that two people share the same one? At first, this might look like a version of the birthday problem.
Birthday Problem
The birthday problem is a probability question that asks, in a set of \(n\) randomly selected people, what is the probability that at least two people share a birthday. Or asked another way, how many people do you need to select to have a greater than 50% chance of getting a matching birthday? I heard this problem for the first time during my first year of graduate school and was surprised that as little as 23 people are needed. The easiest way to solve this problem is to look at it from the other direction:
What is the probability that in a group of \(n\) people, no one shares a birthday?
If \(p(n)\) is the probability that at least two people in a group of \(n\) share a birthday, \(\overline{p}(n)\) is the probability that no one shares a birthday (\(p(n) = 1 - \overline{p}(n)\)).
To avoid anyone sharing a birthday, we would want to add people to the group who have a new birthday. As we keep adding people to the group, the available dates grow smaller. The first person added to the group can have any of the 365 days of the year, the second person must have one of the 364 remaining days, and the third person must have one of the 363 remaining days. The probability of selecting these people (and dates) is grounded in the 365 days of a year. The probability of picking the first person who doesn’t share a birthday is \(p_1 = \frac{365}{365}\), the probability of picking the second person who doesn’t share a birthday is \(p_2 = \frac{364}{365}\), and the probability of picking the first person who doesn’t share a birthday is \(p_3 = \frac{363}{365}\). Since these events are independent, we multiply them to get the probability that three selected people don’t share a birthday:
\({}_{365}P_{n}\) indicates a Permutation which is the number of ways that we can draw \(n\) items from a pool of 365 items, where order matters.
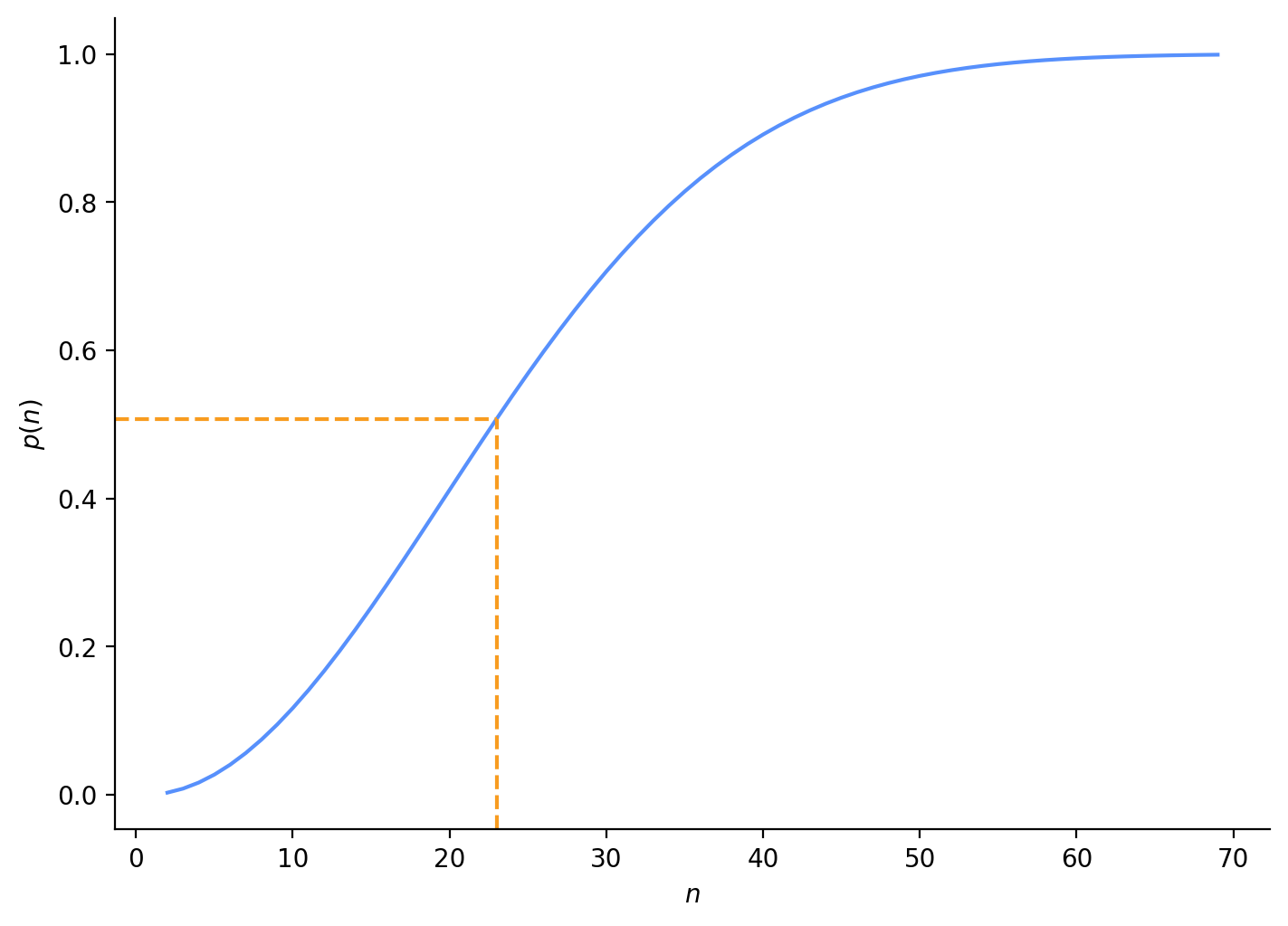
Let’s run this calculation in Python and compare a range of group sizes (Figure 2).
from math import permimport matplotlib.pyplot as pltimport numpy as npimport seaborn as snsfrom cycler import cyclerfrom matplotlib import rcParams%config InlineBackend.figure_format ='retina'%load_ext watermarkpetroff_6 = cycler(color=["#5790FC", "#F89C20", "#E42536", "#964A8B", "#9C9CA1", "#7A21DD"])rcParams["axes.spines.top"] =FalsercParams["axes.spines.right"] =FalsercParams["axes.prop_cycle"] = petroff_6# array of 2-100 people in our groupn_array = np.arange(2, 101, dtype="int")prob_array = np.zeros(shape=n_array.shape)# stopping criteria if our probability is nearly 1eps =1e-3for i, n inenumerate(n_array):# calculate probability for each number of people in group prob_array[i] =1- perm(365, n.item()) / (365** n.item())# stop early if we approach probability of 1if (1- prob_array[i]) < eps: prob_array = prob_array[:i] n_array = n_array[:i]break# plot probability for each group size, indicating first group size with probability > 0.5def plot_match_curve(n_array, prob_array, ax): ax.plot(n_array, prob_array) idx = np.argmax(prob_array >0.5)print(f"Group size (n): {n_array[idx]}, probability: {prob_array[idx]:.3f}") y_lim = ax.get_ylim() x_lim = ax.get_xlim() ax.vlines(n_array[idx], ymin=y_lim[0], ymax=prob_array[idx], linestyle="--", color="C1") ax.hlines(xmin=x_lim[0], xmax=n_array[idx], y=prob_array[idx], linestyle="--", color="C1") ax.set_xlim(x_lim) ax.set_ylim(y_lim) ax.set_xlabel("$n$") ax.set_ylabel("$p(n)$")fig, ax = plt.subplots(figsize=(7, 5), layout="constrained")plot_match_curve(n_array, prob_array, ax);
Group size (n): 23, probability: 0.507
Figure 2: Birthday problem
We got that right answer (\(n\) = 23), which is good. Let’s apply the same method with our telephone line number collision.
Line Number Collision as Birthday Problem
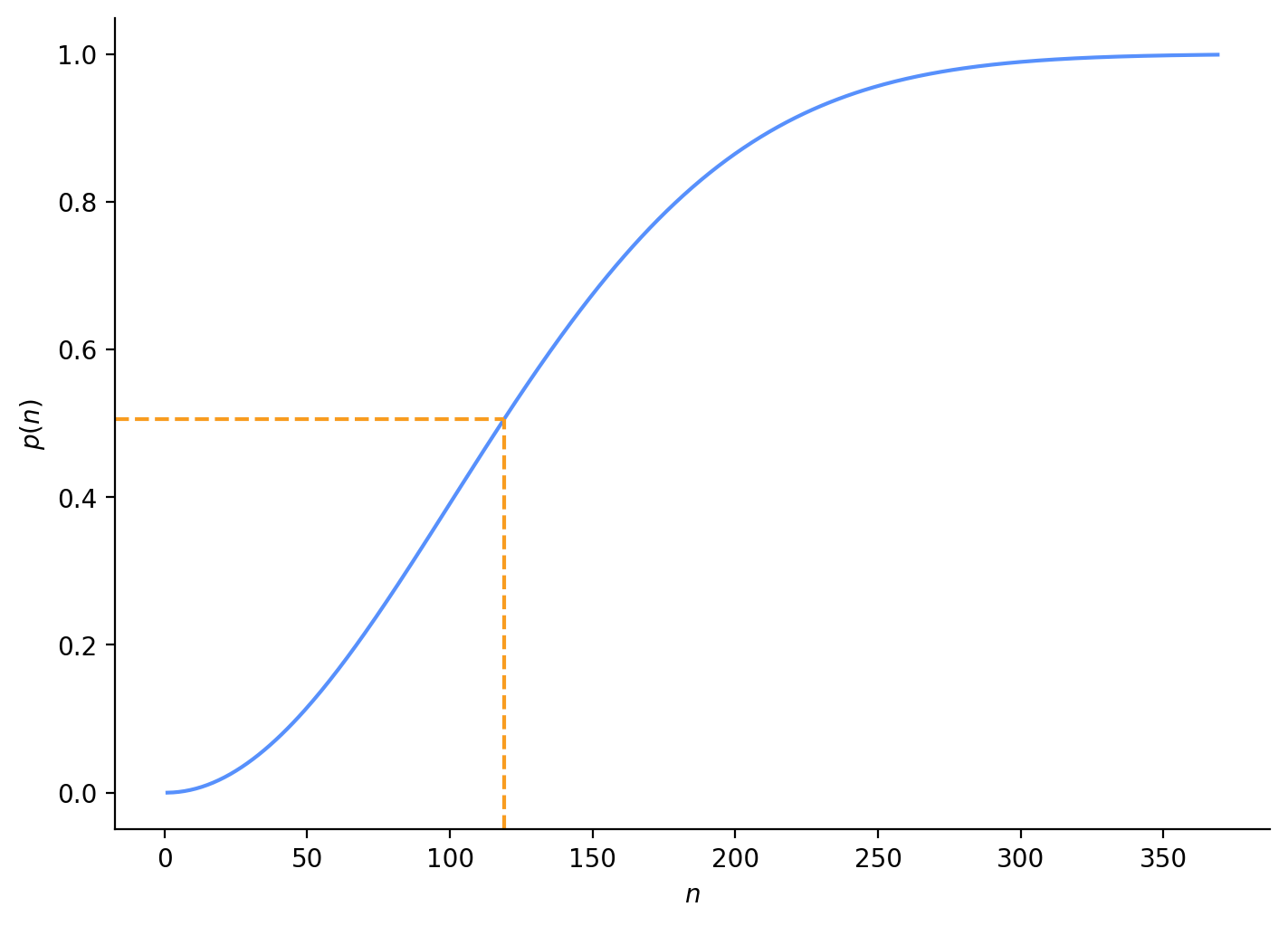
If we follow the birthday problem structure, instead of 365 days of the year, we have 10,000 unique line numbers. We have a new probability formula, which we can use in our Python code (Figure 3):
# array of 1-500 people in our groupn_array = np.arange(1, 501, dtype="int")prob_array = np.zeros(shape=n_array.shape)# stopping criteria if our probability is nearly 1eps =1e-3for i, n inenumerate(n_array):# calculate probability for each number of people in group prob_array[i] =1- perm(10000, n.item()) / (10000** n.item())# stop early if we approach probability of 1if (1- prob_array[i]) < eps: prob_array = prob_array[:i] n_array = n_array[:i]break# plot probability for each group size, indicating first group size with probability > 0.5fig, ax = plt.subplots(figsize=(7, 5), layout="constrained")plot_match_curve(n_array, prob_array, ax);
Group size (n): 119, probability: 0.506
Figure 3: Telephone line number collision as birthday problem
This tells us that if we have at least 119 in the waiting room at the same time, there is at least a 50% probability that there are at least two people with the same 4-digit line number. I don’t think a waiting room would ever have more than 50 people, so 119 wouldn’t be a worry. But, like the birthday problem, it’s surprising that with 10,000 line numbers, we only need 119 people to have a greater than 50% chance of having a collision.
Solve Without Replacement
But this is a simple approximation of our real problem. In the birthday problem, when adding people, we are drawing ‘with replacement’. All dates are valid (although in our calculation, we were trying to add people with new birthdays), and our denominators remained the same (365).
But telephone numbers are finite and unique. Combining the permutations of both the area code and prefix numbers, there are 106 telephone numbers that can have the same line number. We will call this quantity \(\text{\#area-prefixes}\). As we add people to our waiting room, their phone number is no longer available in the pool of telephone numbers. In this case, we are drawing ‘without replacement’. Additionally, with every person/phone number added to our waiting room, there are an additional 106 numbers we are trying to avoid moving forward.
where \(\displaystyle{\prod_{i=1}^{n}}\) is a product operator.
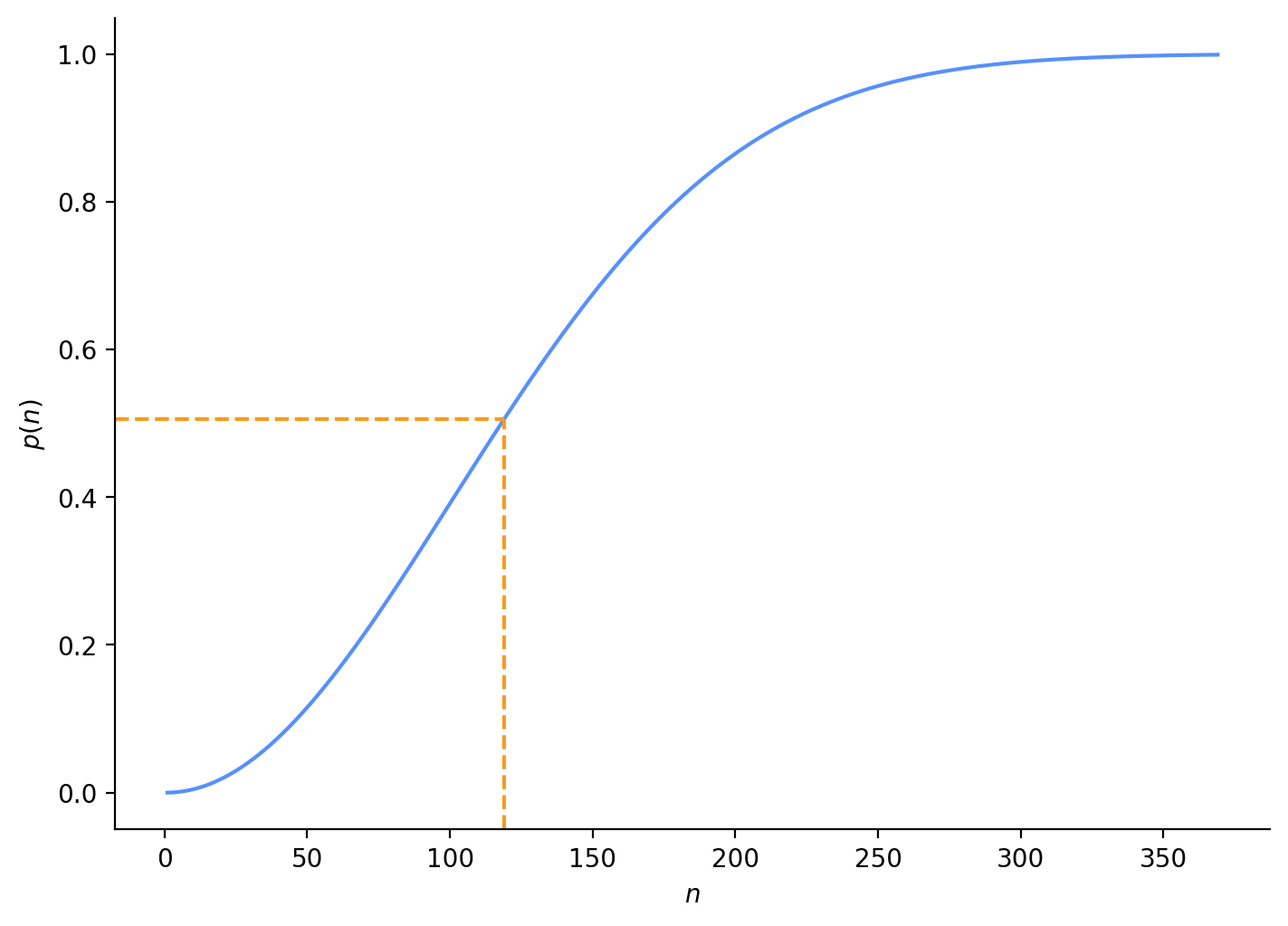
Let’s see how handling the finite reality of phone numbers changes our result (Figure 4):
# array of 1-2000 people in our groupn_array = np.arange(1, 2_000, dtype="int64")prob_array = np.zeros(shape=n_array.shape)num_line_numbers =10**4num_area_prefixes =10**6# stopping criteria if our probability is nearly 1eps =1e-3prob =1for i, n inenumerate(n_array):# calculate probability for each number of people in group prob_num = (num_line_numbers - n +1) * num_area_prefixes prob_denom = num_area_prefixes * num_line_numbers - n +1 prob_n = prob_num / prob_denom prob = prob * prob_n prob_array[i] =1- prob# stop early if we approach probability of 1if (1- prob_array[i]) < eps: prob_array = prob_array[:i] n_array = n_array[:i]break# plot probability for each group size, indicating first group size with probability > 0.5fig, ax = plt.subplots(figsize=(7, 5), layout="constrained")plot_match_curve(n_array, prob_array, ax);
Group size (n): 119, probability: 0.506
Figure 4: Telephone line number collision without replacement
Interestingly, we get the same result! We must have so many \(\text{\#area-prefixes}\) that it is as though we are sampling with replacement.
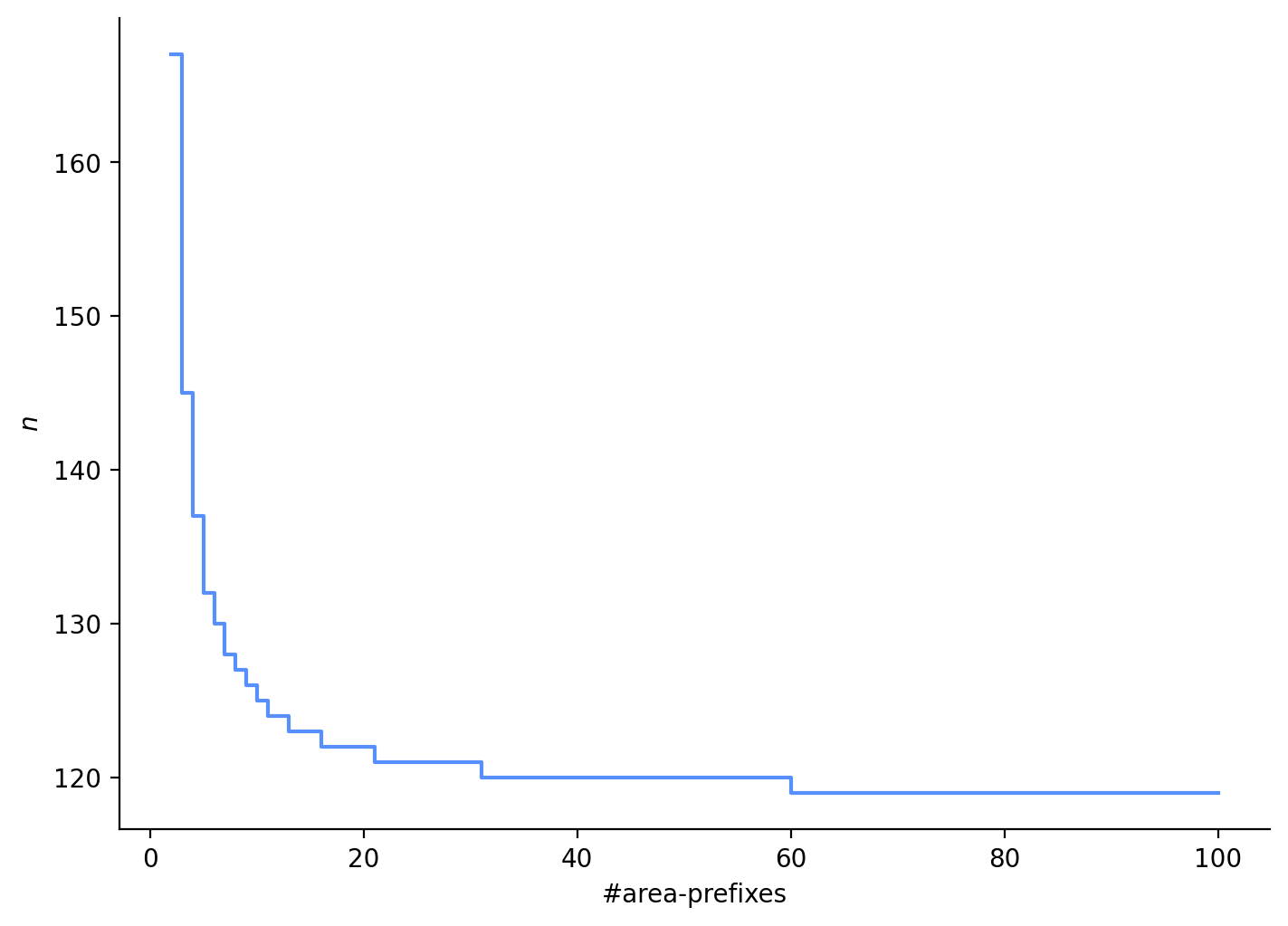
But that makes me wonder, what is the threshold at which \(\text{\#area-prefixes}\) starts to make a difference? 106 is sufficiently high enough, but let’s see where the results change (Figure 5).
n_array = np.arange(1, 2_000, dtype="int64")prob_array = np.zeros(shape=n_array.shape)num_line_numbers =10**4num_area_prefixes_array = np.arange(2, 101)greater_half_prob = np.zeros(shape=num_area_prefixes_array.shape)eps =1e-3for j, num_area_prefixes inenumerate(num_area_prefixes_array): prob =1for i, n inenumerate(n_array):# calculate probability for each number of people in group prob_num = (num_line_numbers - n +1) * num_area_prefixes prob_denom = num_area_prefixes * num_line_numbers - n +1 prob_n = prob_num / prob_denom prob = prob * prob_nif (1- prob) >0.5: greater_half_prob[j] = n_array[i]breakfig, ax = plt.subplots(figsize=(7, 5), layout="constrained")ax.step(num_area_prefixes_array, greater_half_prob, where="post")ax.set_xlabel("#area-prefixes")ax.set_ylabel("$n$");
Figure 5: Limit of telephone line number model without replacement
We can see that with 60 \(\text{\#area-prefixes}\), we need 119+ people in the waiting room to have a greater than 50% chance of a collision. And with fewer than 60 \(\text{\#area-prefixes}\), we need 120-167 people in order to have a 50% chance of collision. 60 is far lower than the 106 we were previously working with!
In reality, the United States (and its territories) uses 358 area codes, and 210 telephone prefixes are invalid (none start with 0, prefixes that end with 11 are reserved, and two others aren’t used). This gives us 790 \(\text{\#area-prefixes}\). Even if we further restrained our problem to consider a waiting room that only served a single area code, there would still be 790 telephone prefixes, and therefore 790 \(\text{\#area-prefixes}\) in use.
If we revisit the probability formula we created above:
we can see that as \(\text{\#area-prefixes}\) grows, the \(-n + 1\) term in the denominator becomes insignificant, and effectively goes to 0. At that point, \(\text{\#area-prefixes}\) can be factored out of every term in the fraction, and we are left with:
which is the same setup as our birthday problem formula.
Conclusion
Starting with a simplification and using the birthday problem as a model, we found that we need at least 119 people in the waiting room to have a telephone line number collision. Even when considering the valid/in-use area codes and prefixes used in the United States, we still need at least 119 people. This holds true even if we used a single area code (and all valid prefixes within it)! There is still a chance of collisions, but we can see how unlikely they are in a normal-sized waiting room.
Appendix: Environment Parameters
%watermark -n -u -v -iv -w
Last updated: Wed Nov 01 2023
Python implementation: CPython
Python version : 3.11.5
IPython version : 8.16.1
seaborn : 0.13.0
numpy : 1.25.2
matplotlib: 3.8.0
Watermark: 2.4.3